API Bulk Ingesting Logs
Author: Roger C.B. Johnsen
Introduction
In this section, we will learn how to import logs into OpenSearch, a process known as log ingestion. There are many methods for ingesting logs into OpenSearch, but we will focus on a script that uses the Python API. The script will read an Ndjson log file of your choice and ingest the data into OpenSearch. In this chapter, we will work within the Alma Linux instance, executing the Python script locally. Alternatively, this procedure can be executed from another machine as well by changing endpoint address in the settings for the Python script.
This script included on this page is not a Swiss army knife solution that parses all log formats on the planet. It is meant as an example on how to use the OpenSearch API. Further customizations to fit your log formats are expected. Please feel free to use the included script for inspiration.
The included script is also available on Github
Setting up a virtual environment
Whenever we work with Python we should establish a sandbox environment. We do this to avoid polluting the native Python environment. In Alma, start by creating a working folder in your home directory and navigate into it. Then, create a virtual environment named “env”, like so:
python3 -m venv envWhen working on a Python project, it’s good practice to create a virtual environment for each project. This will save you a lot of trouble in the long run by preventing conflicts between packages and other issues. Once created, you can activate the environment as follows:
source env/bin/activateYou can see the environment has been loaded by the “(env)” prefix on command line, like so:
(env) [hunter@localhost Ingester]$ Installing necessary Python libraries
To communicate with OpenSearch, we need a Python package that simplifies our work—opensearch-py is the library for that. We also need a package to handle date and time operations more easily, for which we’ll use pendulum. To handle configuration settings, we read important settings from a Toml file using the “toml” library. Instead of installing each package manually using pip, we’ll create a file named requirements.txt and add the following lines:
opensearch-py
pendulum
tomlThis allows us to install all the required packages at once with the following command:
pip install -r requirements.txtPython bulk indexer
Now, with the virtual environment loaded and requirements installed, we can finally start ingesting data. In this chapter we will focus on ingesting a ndjson log using the provided Python script, you can also download a possibly more recent version from here .
A note on Ndjson format
Ndjson (Newline Delimited JSON) is a format for storing or streaming structured data that consists of individual JSON objects separated by newline characters. Each line in an NDJSON file represents a single JSON object, making it easy to process large datasets line by line. This format is particularly useful for log files, data streams, or any situation where you need to handle large amounts of JSON data incrementally.
A log in ndjson format typically looks like this and has a .ndjson file extension:
[
{ "datetime": "datetime", "key_1": "value", "key_2": "value"},
{ "datetime": "datetime", "key_1": "value", "key_2": "value"},
]Take note of the “datetime” key. Typically, there is a field that indicates when the event occurred. Before ingesting the log, you should identify this field. Later, you will use this field to set up a time mapping in OpenSearch.
The ingestion script
The following is a Python script that ingests the log file. To keep the code base somewhat clean, I have chosen to read credentials and other settings from a file called settings.toml located in the same folder as the main script itself. Go ahead and create the file settings.toml and add the following content (adjust to your environment):
hostname = "https://127.0.0.1:9200"
username = "admin"
password = ""
use_ssl = trueThe Python script looks like this. We will not go into details on every aspect of it, but I’ll guide you through some important aspects (please read the entire script anyway):
from opensearchpy import OpenSearch, helpers
from pprint import pprint
import argparse
import os
import json
import pendulum
import re
import sys
import urllib3
import toml
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def run():
try:
parser = argparse.ArgumentParser()
parser.add_argument("logfile")
args = parser.parse_args()
# Load credentials from TOML file
with open("settings.toml", "r") as settings_file:
settings = toml.load(settings_file)
# Ask user for the index name
index_name = input("Enter the index name: ")
# Initialize the OpenSearch client
os_client = OpenSearch(
http_auth=(
settings["username"],
settings["password"]
),
verify_certs=False,
use_ssl=settings["use_ssl"],
retry_on_timeout=True,
timeout=60
)
NOW = pendulum.now()
# Check if the file exists
if not os.path.exists(args.logfile):
print("Input Correct File Path")
raise ValueError("Invalid file path provided")
# Open the file safely
try:
with open(args.logfile, 'r') as log_file:
logs = log_file.readlines()
except Exception as e:
print(f"Error reading file: {e}")
sys.exit(1)
# Check if the index exists, if not create it with the desired field limit
if not os_client.indices.exists(index=index_name):
print(f"Index '{index_name}' does not exist. Creating it now.")
try:
os_client.indices.create(
index=index_name,
body={
"settings": {
"index.mapping.total_fields.limit": 2000 # Set desired field limit here
}
}
)
print(f"Index '{index_name}' created successfully with field limit 2000.")
except Exception as e:
print(f"Error creating index: {e}")
sys.exit(1)
else:
print(f"Index '{index_name}' already exists. Updating field limit to 2000.")
try:
os_client.indices.put_settings(
index=index_name,
body={
"index.mapping.total_fields.limit": 2000 # Adjust this number as needed
}
)
print(f"Field limit for index {index_name} updated successfully.")
except Exception as e:
print(f"Error updating field limit: {e}")
sys.exit(1)
# Bulk indexing
try:
helpers.bulk(os_client, batch_trace_logs(index_name, logs, NOW), request_timeout=60)
print("Bulk indexing completed successfully.")
except Exception as e:
print(f"Error during bulk indexing: {e}")
sys.exit(1)
except FileNotFoundError:
print("Settings file not found.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
sys.exit(1)
def set_date_time(json_item_copy, NOW):
# Adjust the timestamp logic only
current_timestamp = pendulum.parse(json_item_copy['_source']['@timestamp'])
try:
# Safely subtract a day
new_timestamp = current_timestamp.subtract(days=1)
except ValueError:
new_timestamp = current_timestamp.set(day=NOW.day, year=NOW.year, month=NOW.month)
return str(new_timestamp)
def batch_trace_logs(index_name, logs, NOW):
i = 0
count = 0
for item in logs:
count += 1
if i == 10000:
print(f"Bulk Indexed {count} logs")
i = 0
json_item = json.loads(item) # No need for deepcopy
# Use the user-provided index name and update the timestamp
new_timestamp = set_date_time(json_item, NOW)
json_item['_source']['@timestamp'] = new_timestamp
yield {
"_index": index_name, # Use provided index name directly
"_source": json_item['_source'],
'_op_type': "create"
}
i += 1
if __name__ == "__main__":
run()To run it, simply enter this command and follow the onscreen instructions:
python3 shipper.py logfile.ndjsonThis Python script is designed to efficiently ingest Ndjson based logs into OpenSearch. It starts by importing necessary libraries and reading and setting up user-specific settings such as the OpenSearch server hostname, username, and password. After initializing the OpenSearch client, the script retrieves the log file path from the command-line arguments and verifies its existence.
A key function within the script adjusts the timestamps of log entries to ensure they are recent, setting them to either today or yesterday. The script processes the log entries in batches, adjusting their timestamps and preparing them for bulk indexing. It periodically reports progress to keep the user informed.
The script uses OpenSearch’s bulk helper to efficiently index the processed log entries into OpenSearch. This process ensures that the log data is up-to-date and ready for analysis and querying in OpenSearch.
But where does the ingested log end up? The script will ask you the name of the index you want to store the log into. This means, for each log you ingest, you must enter a name. This can be a bit tedious, but on the bright side, you have much power into steering where things goes.
Making the index aliases
This script will parse the Ndjson file and put its content in an index of your choice. However, the index you choose isn’t available in the query tool just yet. You have to set up an “index pattern” first to make it available in “Dashboard”. The following is a generic tutorial on creating such “index patterns”:
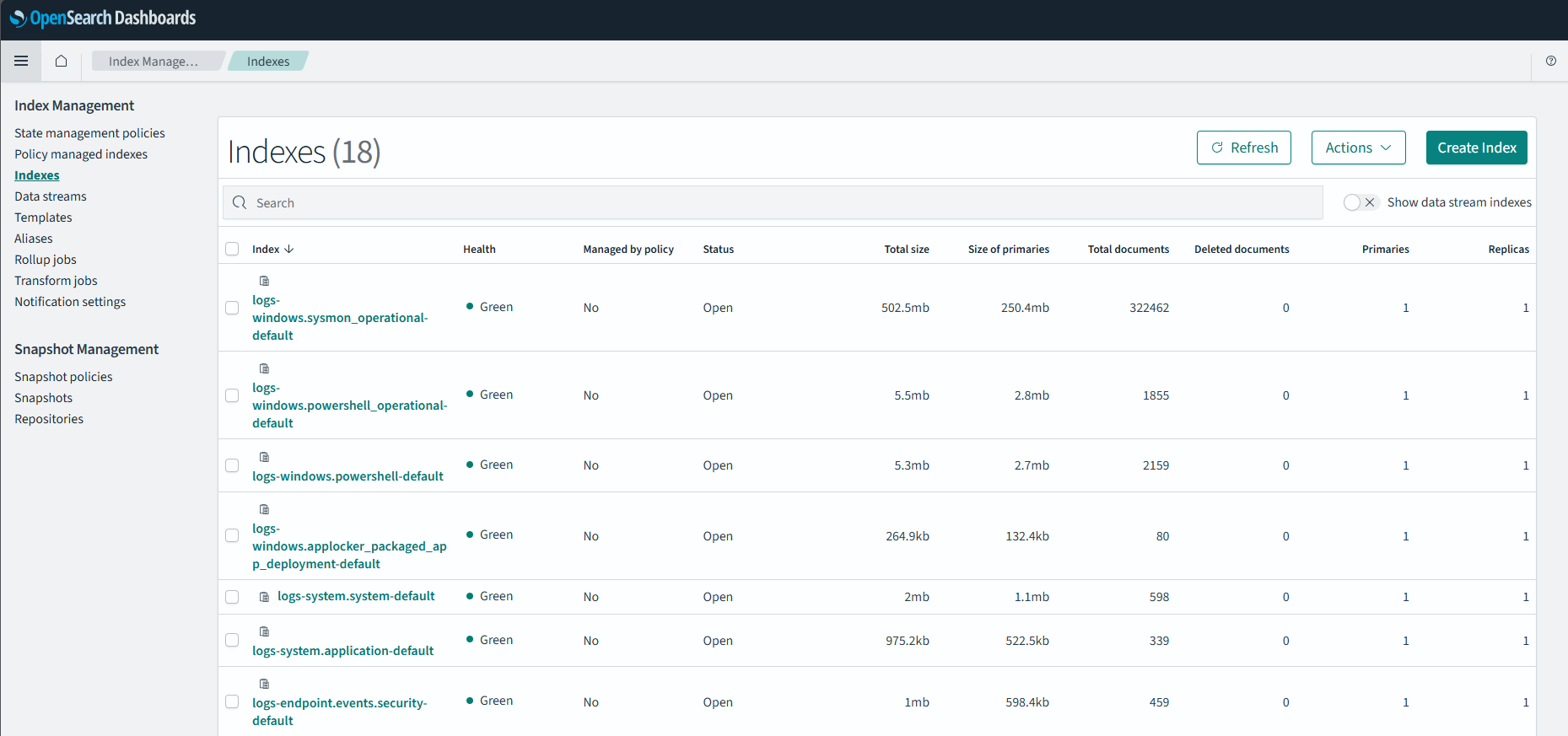
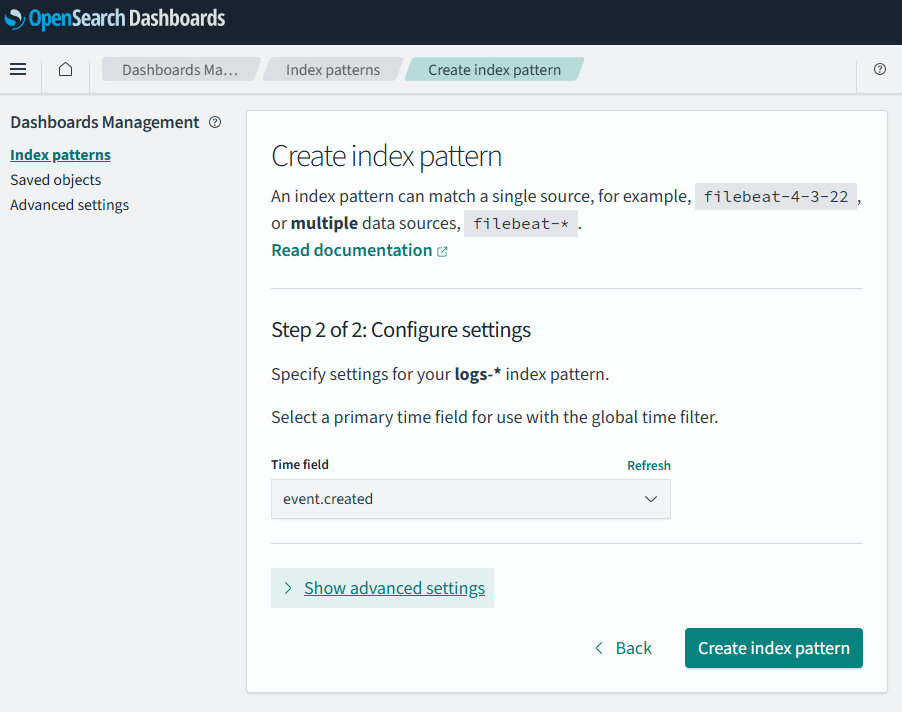
Keep in mind that “Discover” (the main query interface) knows nothing about these indices, thus you can’t search into them directly. You first need to create index aliases for “Discover” to see them. You can do so by reaching the “Dashboard Management” utility by going to this path: “Hamburger menu” -> Management -> “Dashboard Management”:
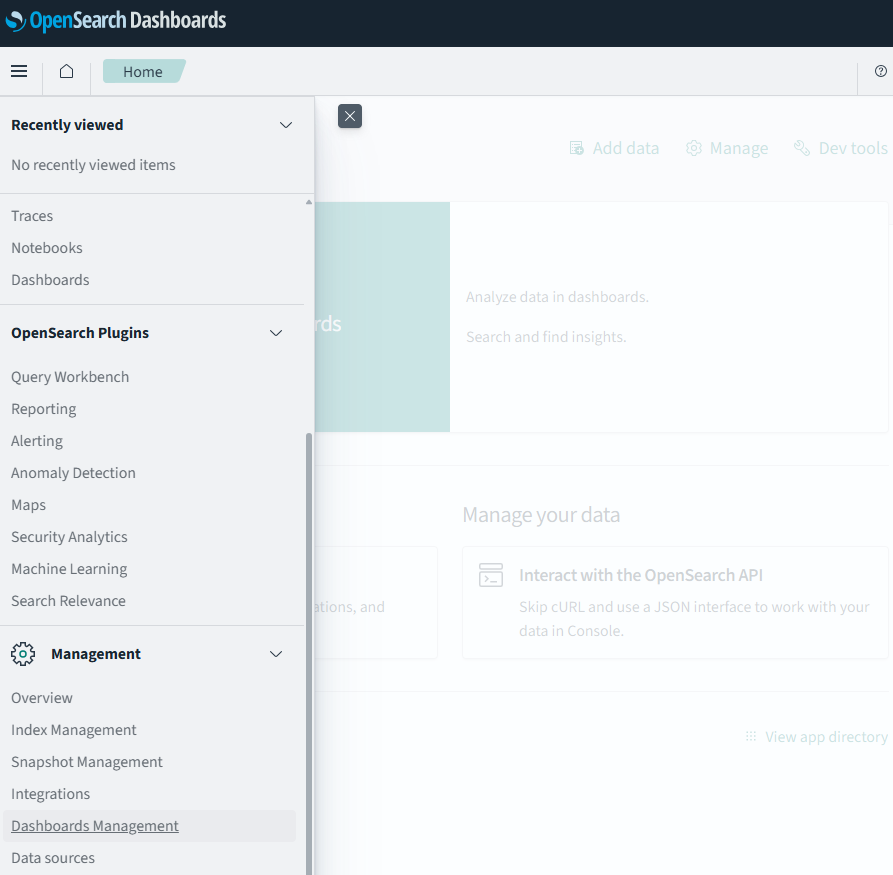
Then select “Index patterns”, then click on the button “Create index pattern”:
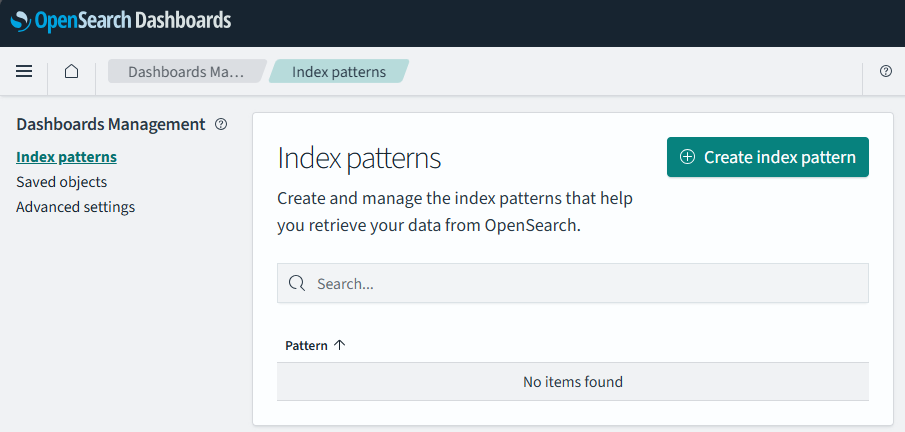
In “Index pattern name” enter a name of choice. Since we now got several logs starting with “logs-”, I find it nice to use the name “logs-*. This will easily match the logs I have an interested in. Keep in mind the name we enter here will show in “Discovery”.
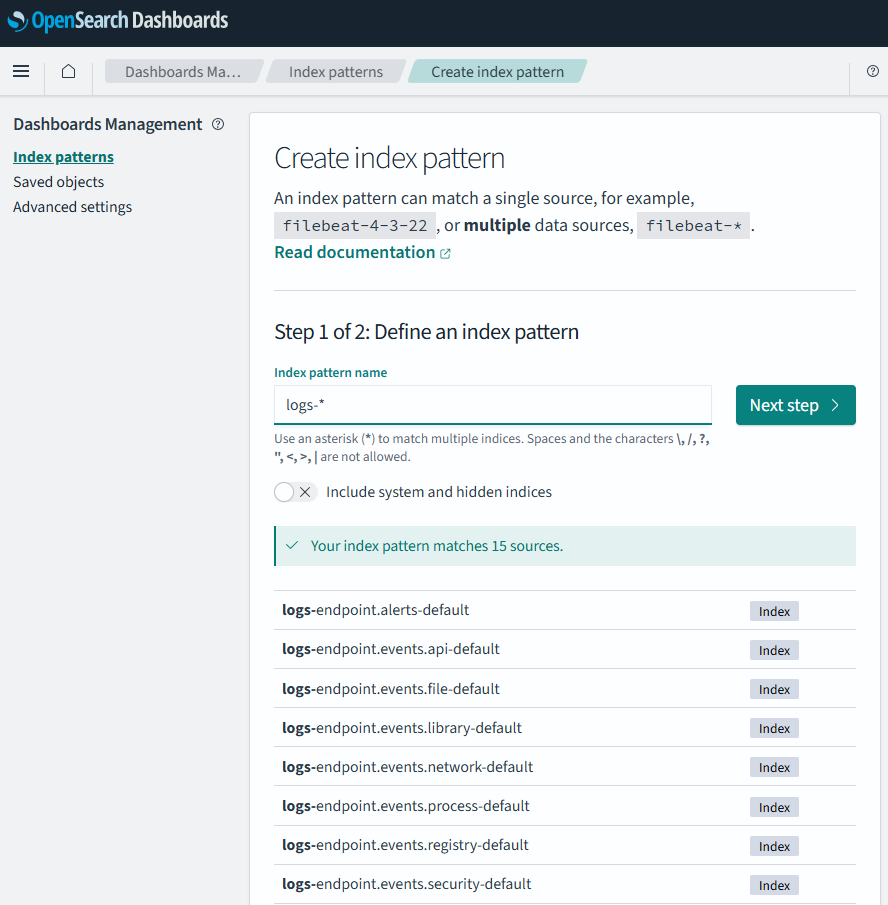
Then point tp a time field to use and click save (as mentioned in the “A note on ndjson format”).
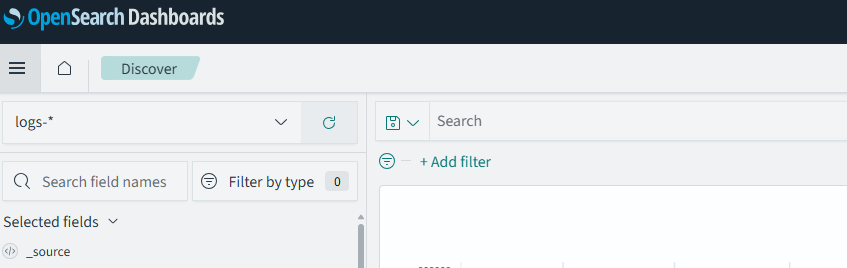
If we go back to “Discover”, we can now see that our “Index alias” is available to us to search in.
Revision
| Revised Date | Comment |
|---|---|
| 06.10.2024 | Script rewritten and content updated accordingly |